GET和POST都是HTTP协议中的两种发送请求的方法,由于HTTP是基于TCP/IP,所以GET和POST的底层也是基于TCP/IP。GET和POST能做的事是一样的,使用GET方法请求时,加上Request body,或者使用POST请求方法是带上Url参数,技术上是完全行得通的。也就是说GET和POST在本质上没有什么太大的区别。
1 关于应用场景
HTTP最早被用来做浏览器与服务器之间交互HTML和表单的通讯协议了后来又被被广泛的扩充到接口格式的定义上。所以在讨论GET和POST区别的时候,需要现确定下到底是浏览器使用的GET/POST还是用HTTP作为接口传输协议的场景。
1.1 浏览器场景
(注:此处特指浏览器中非Ajax的HTTP请求。)
1.1.1 定义
- GET:获取一个资源,比如:获取一个html页面/图片/css/js等。
- POST:在页面里标签会定义一个表单。点击其中的submit元素会发出一个POST请求让服务器做一件事。这件事往往是有副作用的,不幂等的
1.1.2 能否缓存
- GET:允许缓存
- 因为是获取资源,反复读取是不应该对数据有副作用的,比如:GET一下,用户就下单,返回订单已受理,这个是不能接收的。因为是获取资源,是可以对GET请求的数据进行缓存的,可由浏览器本身、代理(如Nginx)或服务端(Etag)缓存,减少带宽。
- POST:不允许缓存
- 不幂等,意味着不能多次执行,也不能缓存。(比如:若下单请求成功页面被缓存了,POST请求不向服务器发送请求,直接返回成功,却没有真正创建订单。)在浏览器中刷新页面,也会有副作用,浏览器会弹出弹框,提示用户是否继续。
1.1.3 携带参数的格式
- GET:Url上携带
- 当在浏览器发出一个GET请求时,就意味着要么用户自己在浏览器地址栏输入,要么就是点击了HTML中a标签的href中的Url。因此不是GET只能用Url,而是浏览器提供的发出GET只能由一个Url触发。
(注:HTTP本身是没有这个限制的!)
- 当在浏览器发出一个GET请求时,就意味着要么用户自己在浏览器地址栏输入,要么就是点击了HTML中a标签的href中的Url。因此不是GET只能用Url,而是浏览器提供的发出GET只能由一个Url触发。
- POST:表单提交
- 浏览器的POST请求都来自表单提交,每次提交浏览器会将要提交的数据编码,并放在HTTP请求的body(请求主体)中。
- 浏览器发出的POST的body格式主要有两种:
- ①、application/x-www-form-urlencoded:传输简单数据,通常以key-value格式传输。
- ②、multipart/form-data:比如传输大文件,或json串等。
(注:当POST一个表单时,Url也可以带参数,只是的标签数据会存在body中)
1.1.4 总结
对于浏览器发请求的场景,可以泛概为:“GET请求没有body,只有Url,请求数据放在Url的querystring中;POST请求的数据在body中“。
1.2 接口场景
接口场景包括:
- ①、浏览器的Ajax api
- ②、IOS/Android的App的Http Client
- ③、Java的Commons-Httpclient/okhttp
- ④、Curl
- ⑤、Postman等工具
当使用HTTP实现接口发送请求时,就没有浏览器中那么多限制,只要符合HTTP协议格式的就可以发送。
HTTP请求包格式如下:
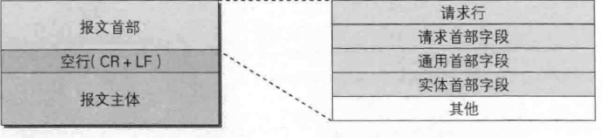
(请求行格式:请求方法 URI 协议版本)
从协议本身看,并没有限制GET不一定没有Body,POST就一定不能把参数放在URI的queryString上。
2 关于安全性
我们经常听到GET方法不如POST方法安全,因为GET使用Url传输,更加容易被看到。但其实从攻击的角度看,无论GET还是POST都不够安全,因为HTTP本身是明文协议。
为了避免传输数据被窃取,必须做从客户端到服务端端加密。通常使用https进行加密传输。(银行、金融、军用等特殊机构,也可以使用其他的加密方式)
相比之下GET有更多的机会被泄露,比如:
- ①、携带私密信息的Url会展示在地址栏,还可以分享给他人,非常不安全。
- ②、从客户端到服务器端,有大量的中间结点,包括网关、代理等,他们的access log通常会输出完整的Url,比如Nginx默认的Access log会打印Url(当然,通过设置,也可打印出body中的内容)。如果Url中携带了敏感数据,就会被记录下来。
避免泄露的唯一手段,就是端端加密(HTTPS等实现)。推荐私密数据传输方法:用POST+body方式。
3 关于编码
有说法说GET的参数只支持ASCII,而POST能支持任意binary,包括中文。但其实针对接口方式实现GET,POST方法实际都能用Url和Body。因此所谓编码确切的说应该是HTTP中Url和Body用什么编码。
3.1 Url编码
3.1.1 字符集合[a-zA-Z0-9$-_.+!*’(),]
RFC1738中规定了一个ASCII的子集[a-zA-Z0-9$-_.+!*’(),],可以不经过编码在Url中使用(尽管空格也是ASCII字,但是不能直接用在Url中)。
1 | Thus, only alphanumerics, the special characters "$-_.+!*'(),", and |
3.1.2 特殊字符和中文
有一个编码方式Percent encoding,可以将特殊字符和中文编码,甚至binary data编码为Url支持的字符。
(这个编码方式只管把字符转换成Url可用字符,并不管字符集编码)
3.2 Body编码
Body中有一个Content-Type来明确定义格式,如:
1 | POST xxxxxx HTTP/1.1 |
3.3 总结
Body和Url都可以提交中文给后端,但是POST的规范好一些,比较不容易出错。
4 请求次数
上面的请求报文可大致分为“报文首部”和“报文主体”两个部分。
使用HTTP时大家会有一个约定,即所有的“控制类”信息应该放在请求头,具体的数据放在请求体里。于是服务器端在解析时,总是先完全解析全部请求头,这样,服务器端总是希望能够了解请求的控制信息后,就能决定这个请求怎么进一步处理,是拒绝,还是根据Content-type去调用相应的解析器处理数据或是zero copy转发。
客户端就能做一些优化,比如内部设定一次POST的数据超过1KB就先只发“请求头”,否则就一次性全发。客户端甚至还可以做一些Adaptive的策略,统计发送成功率,如果成功率很高,就总是全部发等等。不同浏览器,不同的客户端(curl,postman)可以有各自的不同的方案。不管怎样做,优化目的总是在提高数据吞吐和降低带宽浪费上做一个折衷。
因此到底是发一次还是发N次,客户端可以很灵活的决定。因为不管怎么发都是符合HTTP协议的,因此我们应该视为这种优化是一种实现细节,而不用扯到GET和POST本身的区别上。更不要当个什么世纪大发现。
5 关于Url的长度
因为上面提到了不论是GET和POST都可以使用URL传递数据,所以我们常说的“GET数据有长度限制“其实是指”URL的长度限制“。HTTP协议本身对URL长度并没有做任何规定。实际限制是由客户端/浏览器以及服务器端决定的。
5.1 浏览器
不同浏览器不一样,
参考资料:
1、99% 的人都理解错了 HTTP 中 GET 与 POST 的区别【面试必问】
2、GET和POST到底有什么区别?
3、Percent-encoding